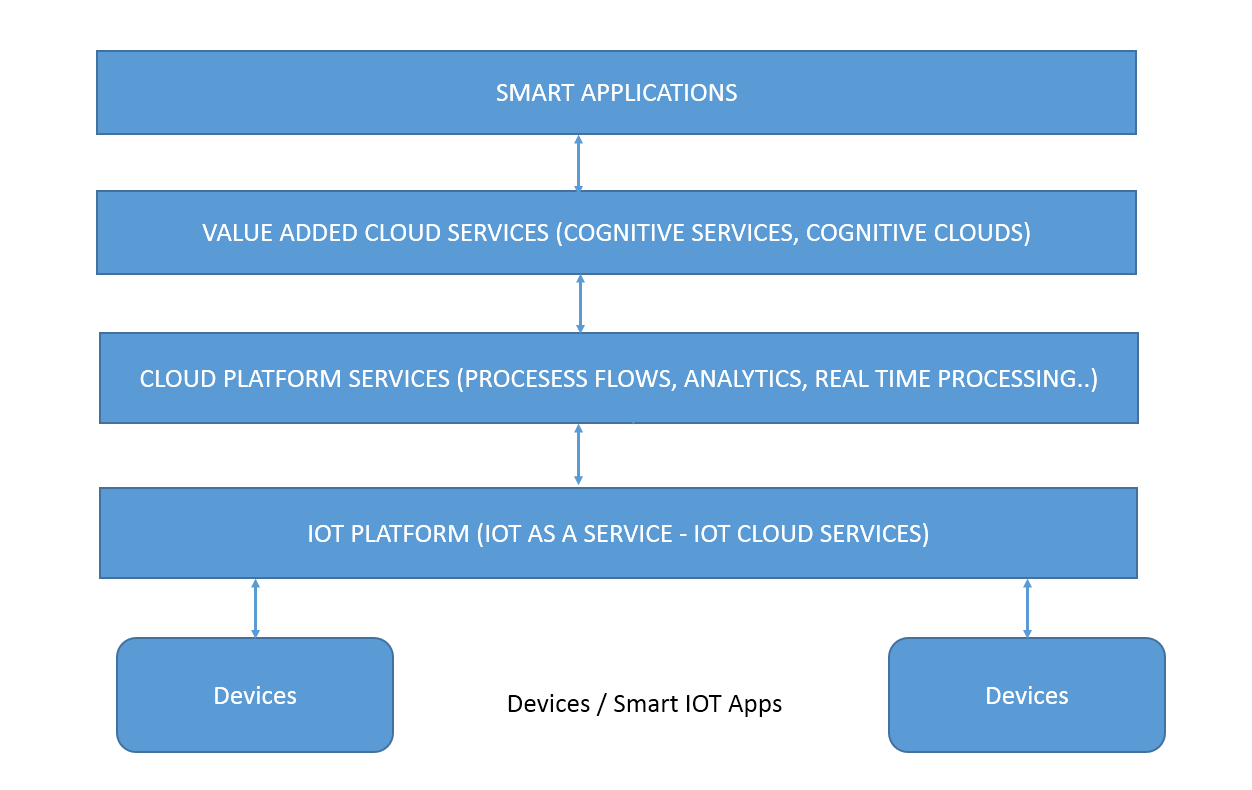
This article is part of IoT Architecture Series - https://navveenbalani.dev/index.php/articles/internet-of-things-architecture-components-and-stack-view/ The following table summaries the various capabilities offered by the
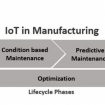
This article is part of IoT Architecture Series - https://navveenbalani.dev/index.php/articles/internet-of-things-architecture-components-and-stack-view/ Large manufacturers have been using some automation and smart technology
The emergence of generative artificial intelligence (AI) is revolutionizing the tech industry, creating unprecedented opportunities for innovation across all roles.
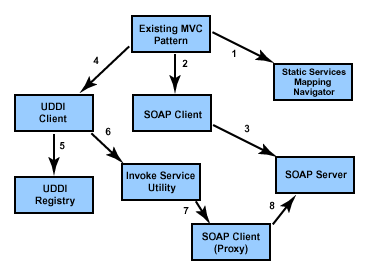
In SOA, we generally talk about identifying the services, implementing it, composing it and governing the services. The key factor that missing out here is
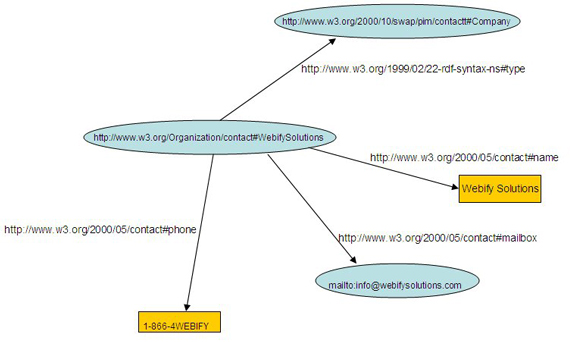
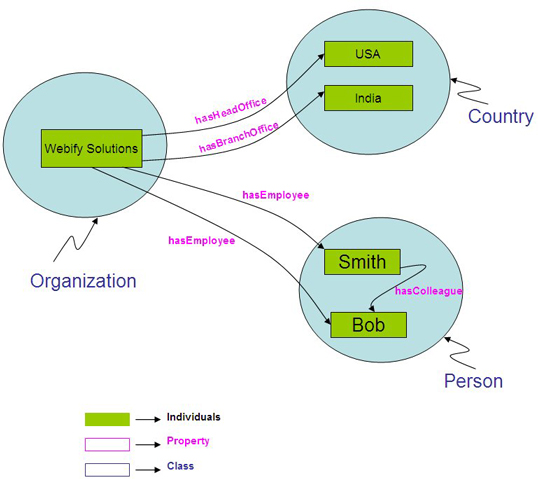
In general, semantics is the study of meaning. (The word "semantic" comes from the Greek semantikos, or "significant meaning," derived from sema, or "sign.") Semantic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















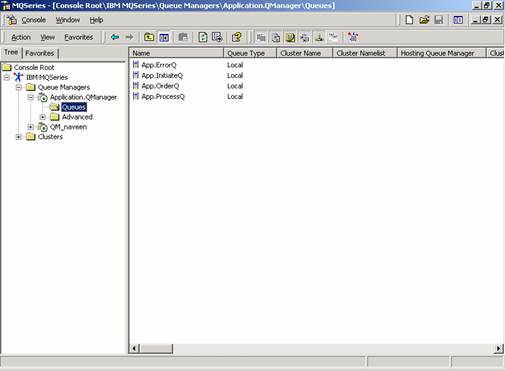
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}